In Part 1 of this series, we built a minimal LLM inference pipeline on Apple Silicon using MLX Swift. In Part 2, we quantized a model from scratch and saw how 4-bit precision makes billion-parameter models tractable on a phone.
This article introduces MLX Embedders, specifically the MLXEmbedders Swift library, and takes a different angle. Instead of generating text, we are going to encode meaning.
A user types: “best hikes near a volcano.” A keyword search returns nothing useful. An embedding-based system returns exactly what they need, because it understands what the words mean, not just what they spell. That capability is what embeddings unlock, and it is the foundation of every serious AI feature in production today: semantic search, recommendation systems, RAG pipelines, and clustering.
The tool for this on Apple Silicon is MLXEmbedders, a Swift library that runs embedding models natively on-device via the MLX framework. This article explains the full theory, the complete pipeline, and the architecture of MLXEmbedders itself, so you can use it correctly in production.
1. Embeddings vs. Large Language Models
Before touching any code, it is worth being precise about what an embedding model is, and what it is not.
A large language model performs a sequence-to-sequence transformation: it takes a sequence of tokens as input and produces another sequence of tokens as output. Its job is generation.
An embedding model performs a sequence-to-vector transformation: it takes a sequence of tokens as input and produces a single dense numerical vector as output. Its job is representation.
LLM: [tokens] → [tokens] (generative)
Embedder: [tokens] → [vector] (representational)This distinction explains why MLXEmbedders is a separate library from MLX Swift LM. The two share underlying infrastructure, tokenization, weight loading, transformer layers, but their output contracts and pooling logic are fundamentally different. Using an LLM where you need an embedder, or vice versa, is not just a style error; it produces meaningless results.
The separation also has a practical implication: embedding models are typically far smaller than LLMs. A capable model like nomic-embed-text has roughly 137M parameters and a 768-dimensional output space. It fits in under 300 MB and runs at thousands of embeddings per second on Apple Silicon. The compute profile is completely different from a 7B autoregressive model.
2. The Mental Model: Position in Meaning Space
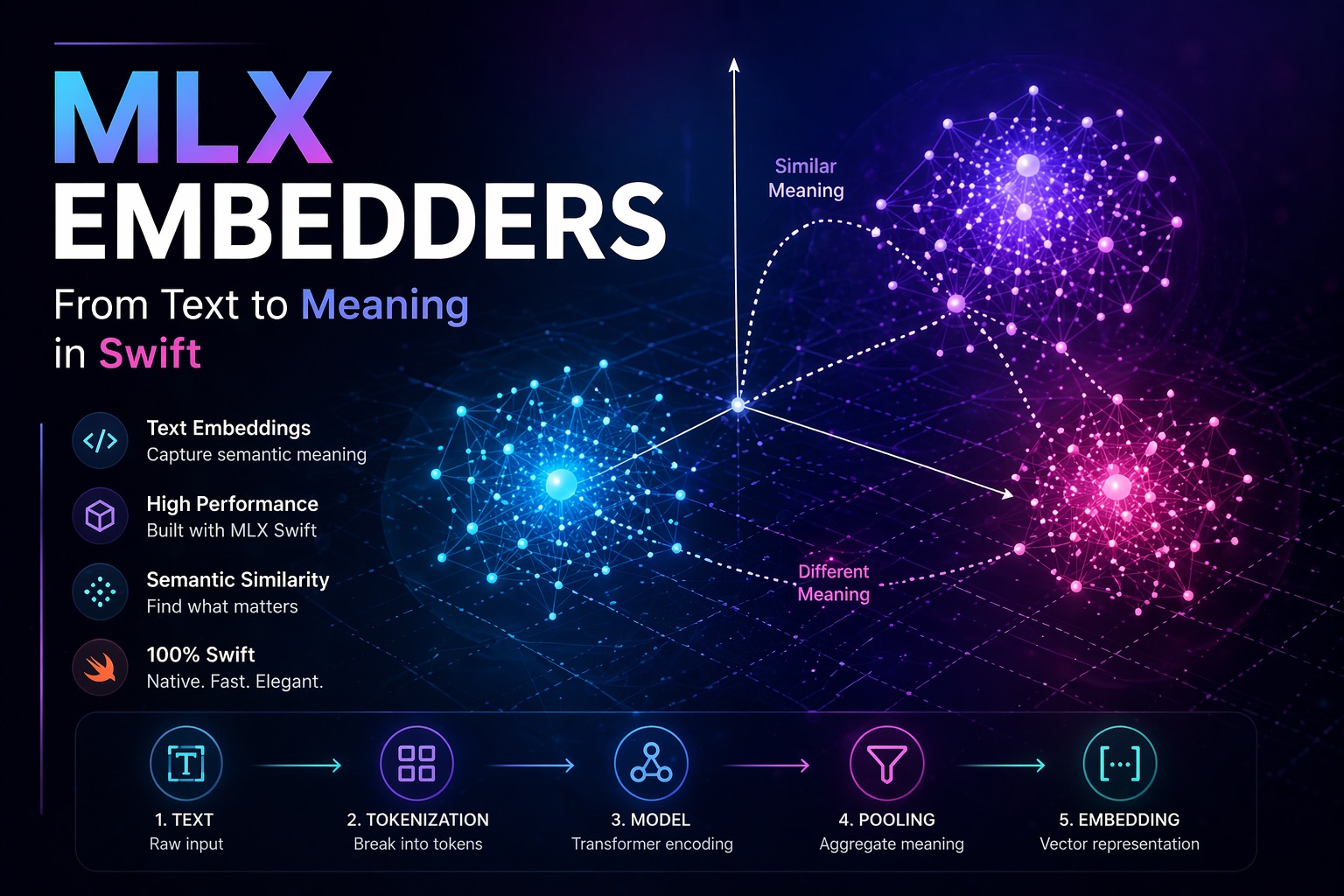
The most useful way to think about an embedding is not as data, it is as a position.
An embedding model has been trained so that semantically similar inputs end up geometrically close in the output vector space. Two sentences that express the same idea will produce vectors that point in nearly the same direction, regardless of the words used. Two sentences on unrelated topics will produce vectors that are far apart, or even orthogonal.
This means that once you have a set of embedded items, documents, product descriptions, user queries, code snippets, the entire problem of finding similar things reduces to finding nearby points. That is a geometry problem, and geometry scales.
Everything else that embeddings enable, semantic search, clustering, classification, RAG, is built on top of this one property.
3. The Full Embedding Pipeline
When you call an embedding model, several distinct transformations happen in sequence. Understanding each step is necessary for using the system correctly, particularly when it comes to pooling.
3.1 Tokenization
The input text is first decomposed into tokens, subword units drawn from the model’s vocabulary. For most modern embedding models, this uses byte-pair encoding (BPE) or WordPiece, the same mechanisms used by BERT-family and GPT-family models.
One important consequence: a sentence like “unmistakable” may be split into ["un", "##mis", "##tak", "##able"]. The model never sees whole words, it sees token IDs, which are integer indices into a learned vocabulary table.
3.2 Token Embeddings
Each token ID is mapped to a learned vector via an embedding lookup table, a weight matrix of shape [vocab_size × hidden_dim]. This is where the first semantic information enters the pipeline: each token has a position in the model’s internal representation space.
Positional embeddings (either absolute or rotary, depending on the architecture) are added at this stage to encode the order of tokens in the sequence.
3.3 Transformer Encoding
The embedded tokens pass through a stack of transformer blocks. Each block applies multi-head self-attention followed by a feed-forward projection, with layer normalization. The attention mechanism allows every token to attend to every other token in the sequence, building up a contextually enriched representation.
After the final transformer layer, you have a hidden state matrix of shape [sequence_length × hidden_dim], one vector per token, each informed by the full context of the sequence.
This is the step that makes embedding models qualitatively different from simple word2vec-style lookup tables. The representation of “bank” in “river bank” is a different vector from “bank” in “bank account”, because the transformer has incorporated the surrounding context.
3.4 Pooling
The transformer output is a matrix, one vector per token. But we need a single vector for the whole sequence. Pooling is the operation that collapses this matrix into a single vector.
This is the most consequential step in the pipeline, and the one most commonly misapplied.
There are two principal strategies:
CLS token pooling. In BERT-style architectures, a special [CLS] token is prepended to the input. The model is trained so that the output vector at position 0 (the [CLS] position) represents the meaning of the entire sequence. Sentence-BERT and many BERT-fine-tuned models use this strategy.
Mean pooling. The hidden states of all non-padding tokens are averaged. This is often more robust than CLS pooling because it aggregates information from the entire sequence rather than relying on a single learned summarizer. Models like nomic-embed-text and all-MiniLM-L6-v2 use mean pooling.
The critical rule: use the pooling strategy the model was trained with. This is documented on the model’s Hugging Face model card. Using mean pooling on a model trained with CLS pooling, or ignoring the attention mask in mean pooling, produces vectors that are numerically plausible but semantically meaningless. There is no error; the system will silently return bad embeddings.
3.5 Normalization
After pooling, the resulting vector is typically L2-normalized, scaled so that its Euclidean norm equals 1. This is a prerequisite for efficient cosine similarity computation: once all vectors are unit-length, cosine similarity simplifies to a dot product, which is both faster and numerically more stable.
Most production embedding models are trained with normalized output vectors. MLXEmbedders handles normalization automatically for supported models, but you should verify this when working with custom model configurations.
4. Similarity: The Core Operation
Once you have embedding vectors, the primary operation you perform on them is measuring similarity.
Cosine similarity is the standard metric for comparing embedding vectors:
func cosineSimilarity(_ a: [Float], _ b: [Float]) -> Float {
let dot = zip(a, b).map(*).reduce(0, +)
let normA = sqrt(a.map { $0 * $0 }.reduce(0, +))
let normB = sqrt(b.map { $0 * $0 }.reduce(0, +))
guard normA > 0, normB > 0 else { return 0 }
return dot / (normA * normB)
}For L2-normalized vectors, the denominator is always 1 by construction, reducing this to a pure dot product, which is why normalization is done at the model level rather than leaving it to the caller.
The score range has clear semantics:
| Score | Interpretation |
|---|---|
| 1.0 | Identical meaning |
| 0.7–0.9 | Highly similar |
| 0.3–0.6 | Related |
| ~0.0 | Unrelated |
| −1.0 | Opposite (rare in practice) |
Dot product and Euclidean distance are also used in some systems, but cosine similarity is the correct choice for normalized embedding vectors and should be the default unless you have a specific reason to deviate.
5. The MLXEmbedders Architecture
MLXEmbedders is part of the mlx-swift-lm package. Its design reflects a clean separation of three concerns: model resolution, weight loading, and concurrency-safe execution.
5.1 EmbedderTypeRegistry
EmbedderTypeRegistry maps the model_type string from a model’s config.json to the corresponding Swift model implementation. It is a static instance of ModelTypeRegistry<EmbeddingModel>. When you load a nomic-embed-text model, the registry resolves "nomic_bert" to NomicBertModel. Other supported architectures include bert, roberta, xlm-roberta, distilbert, qwen3, and gemma3. This is the extensibility point: adding support for a new architecture requires registering a new creator function, not modifying the loading infrastructure.
5.2 EmbedderModelFactory
EmbedderModelFactory is the concrete factory for embedding models. It conforms to the GenericModelFactory protocol from MLXLMCommon and handles the full loading sequence:
- Resolve the model configuration from
config.json - Look up the model class in
EmbedderTypeRegistry - Load weight tensors from
.safetensorsfiles into unified memory - Initialize the tokenizer from the vocabulary and config files
- Load the pooling configuration from
1_Pooling/config.json(or fall back to the model’s built-in strategy) - Return a fully initialized
EmbedderModelContextready for inference
The shared instance is EmbedderModelFactory.shared.
5.3 EmbedderModelContainer (Sendable final class)
EmbedderModelContainer is defined as a public final class conforming to Sendable. It enforces serial access to the underlying MLX state not through Swift’s actor mechanism, but via an internal SerialAccessContainer<EmbedderModelContext>. All reads and mutations are funneled through perform(_:) closures that the container serializes internally, ensuring that only one inference call executes at a time without requiring explicit locking in application code.
public final class EmbedderModelContainer: Sendable {
private let context: SerialAccessContainer<EmbedderModelContext>
public func perform<R: Sendable>(
_ action: @Sendable (EmbedderModelContext) async throws -> sending R
) async rethrows -> sending R {
try await context.read { try await action($0) }
}
}The result is the same concurrency guarantee as an actor, serial, exclusive access, but implemented at the class level through an explicit serial container rather than via actor isolation. This distinction matters when reading the source or reasoning about Sendable conformance: the class is safe to share across concurrency domains, but it is not an actor and carries no actor isolation.
6. What loadModelContainer Actually Does
The entry point for using MLXEmbedders in application code is EmbedderModelFactory.shared.loadContainer(from:using:configuration:). It requires a Downloader and a TokenizerLoader from MLXLMCommon, and the MLXHuggingFace module provides the #hubDownloader() and #huggingFaceTokenizerLoader() macros for Hugging Face Hub integration:
import MLXEmbedders
import MLXHuggingFace
import MLXLMCommon
let container = try await EmbedderModelFactory.shared.loadContainer(
from: #hubDownloader(),
using: #huggingFaceTokenizerLoader(),
configuration: EmbedderRegistry.nomic_text_v1_5
)Behind this call, the framework performs the following:
- Download, if the model files are not already cached locally, they are fetched from the Hugging Face Hub. Only the files required for inference are downloaded: weight shards,
config.json, tokenizer files. - Parse,
config.jsonis deserialized to extract the model architecture, hidden dimensions, layer count, and pooling configuration. - Resolve, the
model_typefield is matched againstEmbedderTypeRegistryto identify the correct Swift model class. - Load weights,
.safetensorsfiles are mapped directly into unified memory. Because unified memory is shared between the CPU and GPU, the loaded tensors are immediately addressable by Metal compute kernels without any copy. - Initialize tokenizer, the vocabulary and merge rules are loaded from
tokenizer.jsonandtokenizer_config.json. - Configure pooling, the pooling strategy is read from
1_Pooling/config.jsonif present; otherwise it falls back to the model’s built-inpoolingStrategy. The supported strategies aremean,cls,first,last,max, andnone. - Wrap in EmbedderModelContainer, the assembled
EmbedderModelContextis placed inside anEmbedderModelContainer(aSendable final classbacked by aSerialAccessContainer) and returned to the caller.
This is not a simple file load. It is full model orchestration, equivalent to what a Python SentenceTransformers pipeline does on the server side, running entirely on-device in a single Swift call.
7. Reference Implementation
The following implementation demonstrates a complete semantic search feature: model loading, embedding a corpus of documents, embedding a user query, and returning ranked results by cosine similarity.
7.1 Package Dependency
Add mlx-swift-lm to your project via Swift Package Manager:
https://github.com/ml-explore/mlx-swift-lmSelect the MLXEmbedders, MLXHuggingFace, and MLXLMCommon library targets (MLXHuggingFace provides the Hugging Face Hub downloader and tokenizer macros).
7.2 Loading the Model
import MLXEmbedders
import MLXHuggingFace
import MLXLMCommon
@MainActor
class EmbeddingService: ObservableObject {
@Published var isLoading = false
private var container: EmbedderModelContainer?
func loadModel() async {
isLoading = true
defer { isLoading = false }
do {
container = try await EmbedderModelFactory.shared.loadContainer(
from: #hubDownloader(),
using: #huggingFaceTokenizerLoader(),
configuration: EmbedderRegistry.nomic_text_v1_5
)
} catch {
print("Model load failed: \(error)")
}
}
}ModelConfiguration values for built-in models are available as static properties on EmbedderRegistry (e.g., .nomic_text_v1_5, .minilm_l6, .bge_small). You can also pass a custom ModelConfiguration(id: "org/model-id") for any Hugging Face Hub model. The download is cached after the first run; subsequent launches are near-instantaneous.
7.3 Embedding a Corpus
EmbedderModelContainer has no top-level encode method. All inference happens inside a perform(_:) closure, which receives an EmbedderModelContext containing the model, tokenizer, and pooling layer:
func embedDocuments(_ documents: [String]) async throws -> [[Float]] {
guard let container else { throw EmbeddingError.modelNotLoaded }
return try await container.perform { context in
let inputs = documents.map {
context.tokenizer.encode(text: $0, addSpecialTokens: true)
}
let maxLength = inputs.reduce(16) { max($0, $1.count) }
let eosId = context.tokenizer.eosTokenId ?? 0
let padded = stacked(inputs.map { elem in
MLXArray(elem + Array(repeating: eosId, count: maxLength - elem.count))
})
let mask = (padded .!= eosId)
let tokenTypes = MLXArray.zeros(like: padded)
let output = context.model(
padded, positionIds: nil, tokenTypeIds: tokenTypes, attentionMask: mask
)
let result = context.pooling(output, normalize: true, applyLayerNorm: true)
result.eval()
return result.map { $0.asArray(Float.self) }
}
}Processing all inputs in a single call is essential for performance, it allows MLX to pad sequences to a uniform length, process them as a single tensor batch, and maximize GPU utilization. Calling this in a loop for individual strings serializes what could be parallel work and typically reduces throughput by 5–10×.
7.4 Semantic Search
struct SearchResult {
let document: String
let score: Float
}
func search(query: String, documents: [String], documentEmbeddings: [[Float]]) async throws -> [SearchResult] {
guard let container else { throw EmbeddingError.modelNotLoaded }
let queryEmbeddings = try await embedDocuments([query])
let queryEmbedding = queryEmbeddings[0]
return zip(documents, documentEmbeddings)
.map { doc, embedding in
SearchResult(
document: doc,
score: cosineSimilarity(queryEmbedding, embedding)
)
}
.sorted { $0.score > $1.score }
}
private func cosineSimilarity(_ a: [Float], _ b: [Float]) -> Float {
zip(a, b).map(*).reduce(0, +) // valid for L2-normalized vectors
}In a production deployment, the document embeddings are pre-computed and persisted, typically in a vector database or a serialized .safetensors file. At query time, only the query needs to be embedded, making the latency of a semantic search query comparable to a simple index lookup.
8. Performance Considerations
8.1 Batching is Mandatory for Throughput
The single most impactful performance decision in an embedding pipeline is batching. Each call to encode involves dispatching Metal compute kernels, padding sequences, and transferring results. The fixed overhead of this dispatch is constant regardless of batch size. Amortizing it over 32 or 64 inputs rather than 1 produces proportionally higher throughput.
For an application that needs to embed a knowledge base of 10,000 documents, the difference between single-item calls and batched calls of size 64 is typically the difference between minutes and seconds.
// Correct: tokenize and embed all documents in one perform call
let embeddings = try await container.perform { context in
// tokenize, pad, and run model in a single batch
embedBatch(documents, context: context)
}
// Avoid: serial per-item perform calls
let embeddings = try await documents.asyncMap { doc in
try await container.perform { context in embedBatch([doc], context: context)[0] }
}8.2 Model Size vs. Quality Trade-offs
Not all embedding models are the same. The relevant dimensions for mobile deployment are:
| Model | Parameters | Output Dim | Size | Quality |
|---|---|---|---|---|
all-MiniLM-L6-v2 | 22M | 384 | ~85 MB | Good for general use |
nomic-embed-text-v1.5 | 137M | 768 | ~290 MB | High quality, recommended |
e5-large-v2 | 335M | 1024 | ~670 MB | Research-grade quality |
For most mobile deployments, nomic-embed-text-v1.5 is the right balance: strong semantic quality, reasonable size, and full support in the MLX community ecosystem.
8.3 Embedding Persistence
Pre-computed embeddings should be persisted across launches. Serializing [[Float]] to a binary file or a local SQLite database is straightforward and avoids re-encoding the same corpus on every startup.
func save(embeddings: [[Float]], to url: URL) throws {
let data = try JSONEncoder().encode(embeddings)
try data.write(to: url)
}
func load(from url: URL) throws -> [[Float]] {
let data = try Data(contentsOf: url)
return try JSONDecoder().decode([[Float]].self, from: data)
}For larger corpora, a purpose-built vector store (even a simple in-memory HNSW index) will outperform linear scan over stored vectors, but for collections under ~50,000 items, brute-force cosine comparison over pre-loaded vectors is fast enough for interactive use.
9. Practical Use Cases
Embeddings are not an experimental capability. They are the foundational primitive behind a family of features that are standard in production applications.
Semantic search. The canonical use case. Index a knowledge base, product catalogue, or document collection as embedding vectors. At query time, embed the user’s query and return the nearest neighbours by cosine similarity. Unlike BM25 or TF-IDF keyword search, this approach handles synonyms, paraphrasing, and cross-lingual queries naturally.
Retrieval-Augmented Generation (RAG). Before calling an LLM (via MLX Swift LM), retrieve the top-k semantically relevant documents and include them in the prompt context. This grounds the model’s responses in specific, current information without fine-tuning. The embedding stage is the retrieval mechanism.
Recommendation systems. Embed user interaction history and item descriptions in the same vector space. Items whose embeddings are close to a user’s embedding history are likely to be relevant. This approach scales to millions of items and works with any modality that can be embedded.
Clustering and topic modelling. Apply k-means or hierarchical clustering to a set of embeddings to discover structure in unstructured text data, support tickets, user feedback, app reviews.
Duplicate detection. Two items with a cosine similarity above a threshold (e.g., 0.95) are likely semantically equivalent, even if their surface text differs. Useful for deduplicating knowledge bases or detecting near-duplicate user submissions.
Classification. Train a lightweight classifier (logistic regression, k-NN) on top of embedding vectors. With a small labelled dataset, this can achieve strong classification performance without fine-tuning the embedding model itself.
10. Common Pitfalls
Wrong pooling strategy. Already covered in detail, but worth repeating: this is the most common and most damaging error. Verify against the model card before shipping.
Missing attention mask in mean pooling. Mean pooling averages the hidden states of all tokens, but padding tokens have no semantic content and must be excluded from the average. Failing to mask padding tokens dilutes the embedding with noise, degrading quality on variable-length inputs.
No normalization. Comparing un-normalized vectors with dot product produces results that are sensitive to vector magnitude rather than direction. Always normalize, or use a cosine similarity function that handles normalization internally.
One-by-one encoding. As discussed in Section 8.1, serial single-item calls forfeit all hardware parallelism. Always batch.
Ignoring model size constraints. A 670 MB embedding model loaded alongside a 4 GB LLM on a device with 8 GB of unified memory leaves minimal headroom for the OS, the application runtime, and the KV cache. Test on the lowest-spec hardware in your target device range, not on a Mac Studio.
Mixing embedding spaces. Vectors from different models are not comparable. A similarity score between a nomic-embed-text embedding and an all-MiniLM embedding is numerically meaningless. If you change models, all stored embeddings must be recomputed.
11. Conclusion
Embeddings are not magic, and they are not opaque. They are the output of a well-defined five-stage pipeline, tokenization, lookup, transformer encoding, pooling, normalization, and understanding each stage is what separates a developer who can use the library from one who can use it correctly.
MLXEmbedders packages this pipeline into a Swift-idiomatic, concurrency-safe API that runs entirely on-device. The architecture is clean: EmbedderTypeRegistry resolves model types, EmbedderModelFactory orchestrates loading, and EmbedderModelContainer, a Sendable final class backed by SerialAccessContainer, enforces thread-safe access to model state. The surface area exposed to application code is small: EmbedderModelFactory.shared.loadContainer(from:using:configuration:), perform(_:) with explicit tokenization logic, and a cosine similarity function.
What you do with that surface area is the more interesting question. Semantic search, RAG, clustering, recommendation, these are not research prototypes. They are production features, and all of them are now achievable on a device in a user’s pocket, without a network connection, without sending data to a third-party API, and without a GPU farm.
The next article in this series will build a complete RAG pipeline on top of MLXEmbedders and MLX Swift LM, combining local embeddings and local generation into a single on-device application.
If you want to go beyond individual techniques and design entire iOS applications around on-device AI, my book covers exactly that.
It combines Clean Architecture, Swift Concurrency, and Foundation Models into production-ready systems, with real code, real trade-offs, and a clear architectural vision.
Frequently Asked Questions
What is MLXEmbedders in Swift?
MLXEmbedders is a Swift library from Apple's MLX ecosystem that runs text embedding models natively on Apple Silicon, including iPhone and Mac. It provides a concurrency-safe API, built around `EmbedderModelContainer`, a `Sendable final class` backed by a serial access container, to convert text into dense vector representations entirely on-device, without sending data to any external API.
What is the difference between an embedding model and an LLM?
An LLM generates text (tokens → tokens), while an embedding model encodes meaning (tokens → a single vector). Embedding models are typically much smaller, 22M to 335M parameters, and optimized for semantic representation rather than generation. They are the core building block behind semantic search, RAG, and recommendation systems.
What pooling strategy should I use with MLXEmbedders?
Always use the pooling strategy the model was trained with. MLXEmbedders supports six strategies: mean, cls, first, last, max, and none. The strategy is read automatically from the model's `1_Pooling/config.json` when present. CLS pooling is typical for BERT-style models; mean pooling is common for models like nomic-embed-text and all-MiniLM. Using the wrong strategy produces numerically valid but semantically meaningless vectors, with no error or warning.
Can MLXEmbedders run on iPhone?
Yes. MLXEmbedders runs entirely on-device via the MLX framework on any Apple Silicon device, including iPhone. The recommended model for mobile is nomic-embed-text-v1.5 (~290 MB), which offers strong semantic quality at a reasonable memory footprint. For constrained devices, all-MiniLM-L6-v2 (~85 MB) is a lighter alternative.
What is the best embedding model for iOS semantic search?
For most iOS deployments, nomic-embed-text-v1.5 (137M parameters, 768-dimensional output) offers the best balance of quality and size. For devices with tighter memory budgets, all-MiniLM-L6-v2 (22M parameters, 384-dimensional output) is a solid lightweight choice supported by the MLX community.
How does on-device embedding with MLXEmbedders compare to a server API?
On-device inference eliminates network latency, removes API costs, and prevents user data from leaving the device. The trade-off is local storage and memory footprint. For semantic search and RAG in iOS apps, on-device inference with MLXEmbedders is the right architectural choice whenever the target device has sufficient unified memory.
References
- Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks, Reimers & Gurevych, 2019
- Nomic Embed: Training a Reproducible Long Context Text Embedder, Nussbaum et al., 2024
- Text Embeddings by Weakly-Supervised Contrastive Pre-training, Wang et al., 2022
- Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks, Lewis et al., 2020
- MLX Swift LM, MLXEmbedders, Apple Inc., 2024
- Efficient and Robust Approximate Nearest Neighbor Search Using HNSW, Malkov & Yashunin, 2018