
Abstract
The proliferation of large-scale neural language models has, until recently, been contingent upon access to remote computational infrastructure. The architectural characteristics of Apple Silicon, most notably its unified memory subsystem, present a substantive departure from this dependency. This article examines MLX Swift, a native Swift binding to Apple’s MLX machine learning framework, as a mechanism for deploying quantized Large Language Models (LLMs) directly on consumer Apple hardware.
We characterize the layered architecture of the MLX ecosystem, contrast its design philosophy with that of Apple’s Foundation Models API, and present a reference implementation demonstrating the complete inference lifecycle: model acquisition, session initialization, and autoregressive text generation. The discussion is grounded in the computational properties of unified memory and their implications for on-device inference efficiency.
1. Introduction
The canonical deployment strategy for Large Language Models has historically presumed the availability of discrete, high-bandwidth GPU memory, a resource absent from consumer-grade mobile and desktop devices. Inference workloads of the magnitude required by billion-parameter models demanded datacenter-class hardware, relegating end-user devices to the role of thin clients in a client–server inference topology.
The introduction of Apple Silicon (M1 through M5) challenges this assumption. By eliminating the PCIe boundary between the CPU and GPU through a unified memory architecture, Apple Silicon enables both compute units to operate on the same physical memory pool without incurring the transfer latency that constitutes a primary bottleneck in conventional GPU inference pipelines.
MLX, a tensor computation framework developed by Apple’s machine learning research team, is designed to exploit this architectural property. Its Swift binding, MLX Swift, exposes this capability at the application layer, providing native Apple developers with the primitives necessary to integrate quantized LLMs into production applications without reliance on external inference services.
This article is structured as follows. Section 2 characterizes the layered architecture of the MLX ecosystem. Section 3 analyzes the performance implications of unified memory for LLM inference. Section 4 contrasts MLX Swift with Apple’s Foundation Models API across several critical dimensions. Section 5 presents a reference implementation covering the complete inference lifecycle, with annotated Swift source. Section 6 examines the role of Hugging Face as the model distribution layer underpinning the MLX ecosystem.
2. The MLX Ecosystem: A Layered Architecture
The MLX ecosystem is organized as a three-tier stack, each layer providing a progressively higher level of abstraction. Understanding the role and boundaries of each tier is essential for reasoning about the performance and extensibility characteristics of the system.
2.1 MLX Core: Tensor Computation Engine
At the foundation of the stack resides MLX Core, a general-purpose tensor computation library implemented in C++. Its design is analogous to frameworks such as NumPy and PyTorch in its provision of:
- Tensor manipulation primitives: creation, indexing, broadcasting, and elementwise operations over n-dimensional arrays
- Composable neural network layers: linear projections, normalization layers, attention mechanisms, and activation functions
- Lazy evaluation and automatic differentiation: a computation graph is constructed and executed on demand, enabling both forward inference and gradient-based optimization
MLX Core’s distinguishing characteristic relative to its contemporaries is its first-class targeting of Apple’s Metal GPU API, ensuring that compute kernels are executed on the GPU without intermediate abstraction overhead.
2.2 MLX-LM: Language Model Specialization
MLX-LM constitutes the second tier, extending MLX Core with capabilities specific to the inference requirements of autoregressive language models:
- Model deserialization: loading of weights from the SafeTensors format as distributed on the Hugging Face Model Hub
- Tokenization: integration with vocabulary files and byte-pair encoding schemes compatible with the model family in use
- Autoregressive decoding: implementation of the token-by-token generation loop, including temperature scaling and sampling strategies
- Key–Value cache management: maintenance of the KV cache across decoding steps to avoid redundant computation of attention over the prompt prefix
2.3 MLX Swift: Native Apple Platform Binding
The uppermost tier, MLX Swift, provides a Swift-idiomatic interface to the MLX C++ core. Its design objectives are twofold: to present a type-safe API amenable to integration with SwiftUI and UIKit application architectures, and to expose the asynchronous concurrency model of Swift, including async/await and structured concurrency via Task, as the primary mechanism for non-blocking inference.
The ChatSession abstraction, central to the reference implementation in Section 5, encapsulates the model weights, tokenizer state, and KV cache within a single object, reducing the surface area exposed to application code.
3. Performance Considerations: Unified Memory and Inference Latency
3.1 The Memory Transfer Bottleneck in Conventional Architectures
In conventional computing architectures, the CPU and GPU maintain distinct memory pools connected via a PCIe bus. During inference, weight tensors must be transferred from host (CPU) memory to device (GPU) memory prior to each forward pass, or maintained persistently in GPU VRAM at the cost of capacity. For models with billions of parameters, this transfer cost is non-trivial, both in latency and in energy consumption.
3.2 Unified Memory Elimination of the PCIe Boundary
Apple Silicon’s unified memory architecture physically collocates CPU and GPU memory into a single high-bandwidth pool. Consequently:
- Weight tensors loaded by the CPU are immediately accessible to the GPU without any explicit transfer operation
- The effective memory bandwidth available to inference kernels is that of the unified pool, up to 800 GB/s on M3 Ultra, rather than the PCIe ceiling of approximately 64 GB/s
- Total addressable memory for model weights is the full system RAM, enabling deployment of models that would otherwise require dedicated GPU VRAM exceeding typical consumer hardware configurations
This architectural property is what renders 4-bit quantized models in the 7B parameter class, requiring approximately 4 GB of weights, tractable on Apple Silicon devices with 8 GB of unified memory.
4. Comparative Analysis: MLX Swift and Apple Foundation Models
Apple provides two distinct pathways for on-device language model inference. Their intended use cases, design constraints, and capability envelopes differ substantially.
| Dimension | MLX Swift | Apple Foundation Models |
|---|---|---|
| Model selection | Any model compatible with MLX-LM (Mistral, Llama, Gemma, Phi, etc.) | Apple-curated models only; not user-selectable |
| Inference control | Full access to sampling parameters, KV cache, and generation loop | Abstracted; no access to generation internals |
| Privacy model | Entirely on-device; no telemetry surface | On-device by design, but API-mediated |
| Integration complexity | Manual dependency management via Swift Package Manager | OS-integrated; available via standard Apple SDK |
| Minimum OS requirement | macOS 13.3 / iOS 16 (MLX Swift requirement) | iOS 26 / macOS 26 (Foundation Models requirement) |
| Primary use case | Research, custom pipelines, model-specific deployments | General-purpose app intelligence features |
The selection between these two approaches is not a matter of quality but of fitness for purpose. Foundation Models is appropriate where OS-level integration, minimal setup, and guaranteed future model updates are desirable. MLX Swift is appropriate where model specificity, inference transparency, or the use of open-weights models is a design requirement.
5. Reference Implementation
The following implementation demonstrates the complete inference lifecycle using MLX Swift: dependency configuration, model acquisition with progress reporting, and single-turn prompted generation. The implementation targets a SwiftUI observable object pattern, though the core logic is architecture-agnostic.
5.1 Dependency Configuration
The mlx-swift-lm package is added to the project via Swift Package Manager using the following repository URL:
https://github.com/ml-explore/mlx-swift-lm5.2 Metal Toolchain Requirement
MLX dispatches all tensor operations to Apple’s Metal GPU API. As a consequence, the Metal toolchain must be installed before the project can be compiled or executed. Absence of this component results in a build failure at the Metal shader compilation stage, irrespective of whether the Swift package dependencies have been resolved correctly.
The toolchain is installed via Xcode → Settings → Components, where a dedicated Metal Toolchain 26.4 entry is listed. Clicking the Get button initiates the download and installation. The following figure illustrates the relevant Xcode interface:
5.3 Model Selection
The reference model is Mistral 7B Instruct v0.3, post-trained for instruction following and distributed in a 4-bit quantized form by the MLX community on the Hugging Face Hub:
mlx-community/Mistral-7B-Instruct-v0.3-4bitThe 4-bit quantization reduces the effective weight size from approximately 14 GB (BF16) to approximately 4 GB, rendering the model deployable on devices with 8 GB of unified memory with sufficient headroom for the KV cache and application runtime.
5.4 Model Acquisition
Download state is represented as a discriminated union, enabling the view layer to express loading progress without coupling to implementation details:
enum DownloadState {
case idle
case downloading(progress: Double)
case downloaded
case error(String)
}The downloadModel() function initiates asynchronous weight retrieval from the Hugging Face Hub. Progress callbacks are dispatched to the main actor to satisfy Swift’s data isolation requirements for observable UI state:
func downloadModel() async {
downloadState = .downloading(progress: 0)
do {
let model = try await loadModel(
id: "mlx-community/Mistral-7B-Instruct-v0.3-4bit"
) { progress in
Task { @MainActor in
self.downloadState = .downloading(
progress: progress.fractionCompleted
)
}
}
chatSession = ChatSession(model)
downloadState = .downloaded
} catch {
downloadState = .error(error.localizedDescription)
}
}Upon successful completion, the deserialized model weights and tokenizer state are encapsulated within a ChatSession instance, which persists the KV cache across subsequent generation calls.
5.5 Autoregressive Text Generation
Generation state is modeled as a binary enum to prevent concurrent invocations:
enum GenerationState {
case idle
case generating
}The generate(prompt:) function delegates prompt encoding, the autoregressive decoding loop, and response detokenization to ChatSession.respond(to:), returning control to the caller upon sequence termination:
func generate(prompt: String) async {
guard let chatSession else { return }
generationState = .generating
do {
output = try await chatSession.respond(to: prompt)
} catch {
output = error.localizedDescription
}
generationState = .idle
}It is worth noting that respond(to:) in this form returns the complete generated sequence as a single String value. Part 2 of this series will replace this call with a streaming variant, yielding tokens incrementally via an AsyncSequence and enabling progressive rendering in the view layer.
6. Model Distribution with Hugging Face
6.1 Overview of the Hugging Face Platform
Hugging Face is an open platform for the hosting, versioning, and distribution of machine learning artifacts, encompassing model weights, datasets, and associated tooling. Its primary interface, the Hugging Face Hub, functions as a centralized repository that has become the de facto standard for the dissemination of open-weights language models within the research and engineering communities.
The Hub provides a uniform namespace for model identification, of the form {organization}/{model-name}, alongside a versioning mechanism based on Git LFS, enabling reproducible weight retrieval across environments. Access is mediated through a REST API and a set of client libraries, making programmatic model acquisition tractable from any language ecosystem with HTTP capability.
6.2 Integration with MLX Swift
MLX Swift relies on the Hugging Face Hub as its exclusive model distribution channel. When loadModel(id:progress:) is invoked, the framework performs the following sequence of operations against the Hub API:
- Repository resolution, the model identifier is resolved to a specific Hub repository, and the repository’s file manifest is retrieved
- Selective file acquisition, only the files required for inference are downloaded: weight shards, the model configuration, and tokenizer assets
- Local caching, retrieved files are persisted to a local cache directory, such that subsequent invocations with the same model identifier do not incur redundant network transfers
- Deserialization, weight tensors are loaded from the SafeTensors format directly into the unified memory pool, where they are immediately addressable by both the CPU and GPU
This design decouples the application developer from the logistics of weight management: network transfer, file integrity verification, and cache invalidation are handled transparently by the framework.
6.3 The MLX Community Organization
The mlx-community organization on Hugging Face serves as the primary distribution point for models adapted for the MLX runtime. Models published under this namespace have undergone a conversion and quantization pipeline that transforms weights from their original training format into representations suitable for efficient execution under MLX:
- Format conversion: weights are converted from PyTorch’s
.binor.safetensorssource format to the MLX-compatible SafeTensors layout expected by MLX-LM - Post-training quantization: weight matrices are quantized to reduced-precision representations, most commonly 4-bit integers, using group-wise quantization schemes that preserve model quality while substantially reducing memory footprint
- Configuration adaptation: the
config.jsonfile is updated to reflect MLX-specific architecture parameters and quantization metadata
As of this writing, the mlx-community organization hosts conversions of the principal open-weights model families, including Mistral, Llama, Gemma, Phi, and Qwen, across multiple quantization levels.
6.4 Model Repository Structure and File Formats
A model repository on the Hugging Face Hub compatible with MLX-LM conforms to a consistent file structure. The principal artifacts are as follows:
| File | Purpose |
|---|---|
config.json | Model architecture specification: layer count, hidden dimensions, attention head configuration, and vocabulary size |
*.safetensors | Weight shards encoded in the SafeTensors format, a zero-copy, memory-mappable binary layout that eliminates deserialization overhead and mitigates the arbitrary code execution risks associated with pickle-based formats |
tokenizer.json | Vocabulary and merge rules for the byte-pair encoding tokenizer |
tokenizer_config.json | Tokenizer metadata: special token identifiers, chat template, and padding configuration |
quantization.json | Quantization scheme parameters: group size, bits per weight, and per-layer quantization decisions |
The reference model employed in Section 5, mlx-community/Mistral-7B-Instruct-v0.3-4bit, exemplifies this structure. Its 4-bit weight representation reduces the aggregate weight size from approximately 14 GB (BF16) to approximately 4 GB, a reduction of 72%, while preserving instruction-following capability at a quality level commensurate with deployment on consumer hardware. This compression ratio is what renders the model tractable on Apple Silicon devices configured with 8 GB of unified memory, where system software, application runtime, and KV cache must compete for the same physical address space as the model weights.
7. Application Demonstration: MLXExplorer
To validate the reference implementation in an end-to-end context, the complete inference pipeline described in Section 5 was integrated into a minimal SwiftUI application, MLXExplorer. The application exercises each stage of the lifecycle in sequence:
- Model acquisition, upon launch, the application initiates an asynchronous download of the
Mistral-7B-Instruct-v0.3-4bitweights from the Hugging Face Hub, exposing download progress as a continuous percentage via theDownloadState.downloading(progress:)case - Session initialization, upon successful weight deserialization, a
ChatSessioninstance is constructed and retained in the view model, encapsulating the KV cache for the duration of the session - Prompted generation, the user submits a natural language prompt via a text field; the application delegates to
ChatSession.respond(to:)and renders the complete response upon termination of the generation loop
The following figure captures the application at runtime, illustrating both the download progress interface and the response rendering upon generation completion:
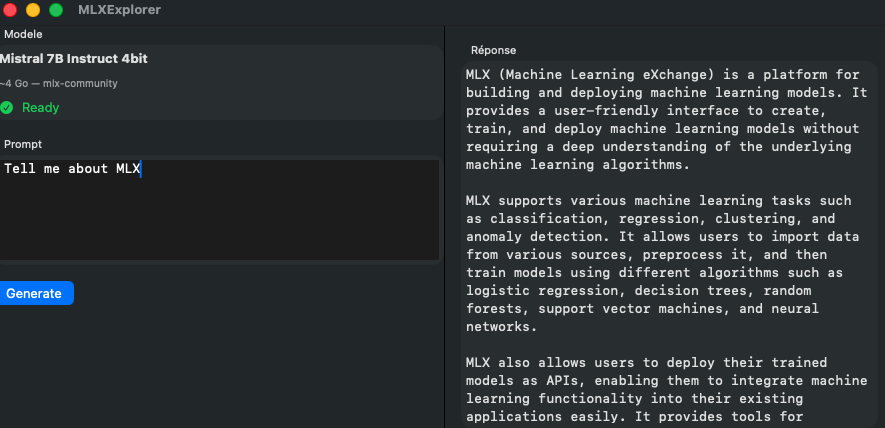
DownloadState. Right: response rendered following a single-turn prompted generation with the locally-resident Mistral 7B model.The application confirms that the complete inference pipeline, from weight acquisition through autoregressive decoding, is operable within a standard SwiftUI application target, without any modification to the application’s entitlements or sandbox configuration.
8. Source Code: MLXExplorer on GitHub
The complete source code for MLXExplorer is publicly available on GitHub:
A minimal SwiftUI application demonstrating end-to-end on-device LLM inference using MLX Swift, covering model download, session initialization, and prompted generation with Mistral 7B on Apple Silicon.
The repository contains the full SwiftUI application described in this article, including the DownloadState and GenerationState state machines, the ChatSession-backed view model, and the interface demonstrated in Figure 2. It is intended as a self-contained reference for developers integrating MLX Swift into their own application targets.
9. Conclusion
This article has presented the MLX Swift framework as a viable mechanism for on-device LLM inference on Apple Silicon. The unified memory architecture of Apple’s M-series system-on-chip eliminates the primary latency bottleneck of conventional GPU inference pipelines, rendering the deployment of 4-bit quantized models in the 7B parameter class tractable on consumer hardware.
The reference implementation demonstrates that the complete inference lifecycle, from model acquisition to autoregressive generation, can be expressed concisely within Swift’s structured concurrency model, with state management patterns compatible with both SwiftUI and UIKit application architectures.
Subsequent investigation will address the following open questions: the throughput characteristics of streaming generation via AsyncSequence; the memory pressure profile of concurrent KV cache maintenance across multiple sessions; and the performance differential between 4-bit and 8-bit quantization schemes on M-series hardware under realistic workloads.
References
- Apple Inc. MLX: A Machine Learning Framework for Apple Silicon. GitHub, 2023.
https://github.com/ml-explore/mlx - Apple Inc. MLX Swift. GitHub, 2023.
https://github.com/ml-explore/mlx-swift - Apple Inc. MLX Swift LM. GitHub, 2024.
https://github.com/ml-explore/mlx-swift-lm - Jiang, A. Q. et al. Mistral 7B. arXiv:2310.06825, 2023.
- Apple Inc. Apple Silicon, Unified Memory Architecture. Apple Developer Documentation, 2024.
- Apple Inc. Foundation Models Framework. Apple Developer Documentation, 2024.
- Hugging Face Inc. Hugging Face Hub Documentation.
https://huggingface.co/docs/hub - Hugging Face Inc. mlx-community Organization. Hugging Face Hub, 2024.
https://huggingface.co/mlx-community - Gante, J. et al. SafeTensors: A Simple, Safe File Format for ML Model Weights. Hugging Face, 2022.
https://github.com/huggingface/safetensors