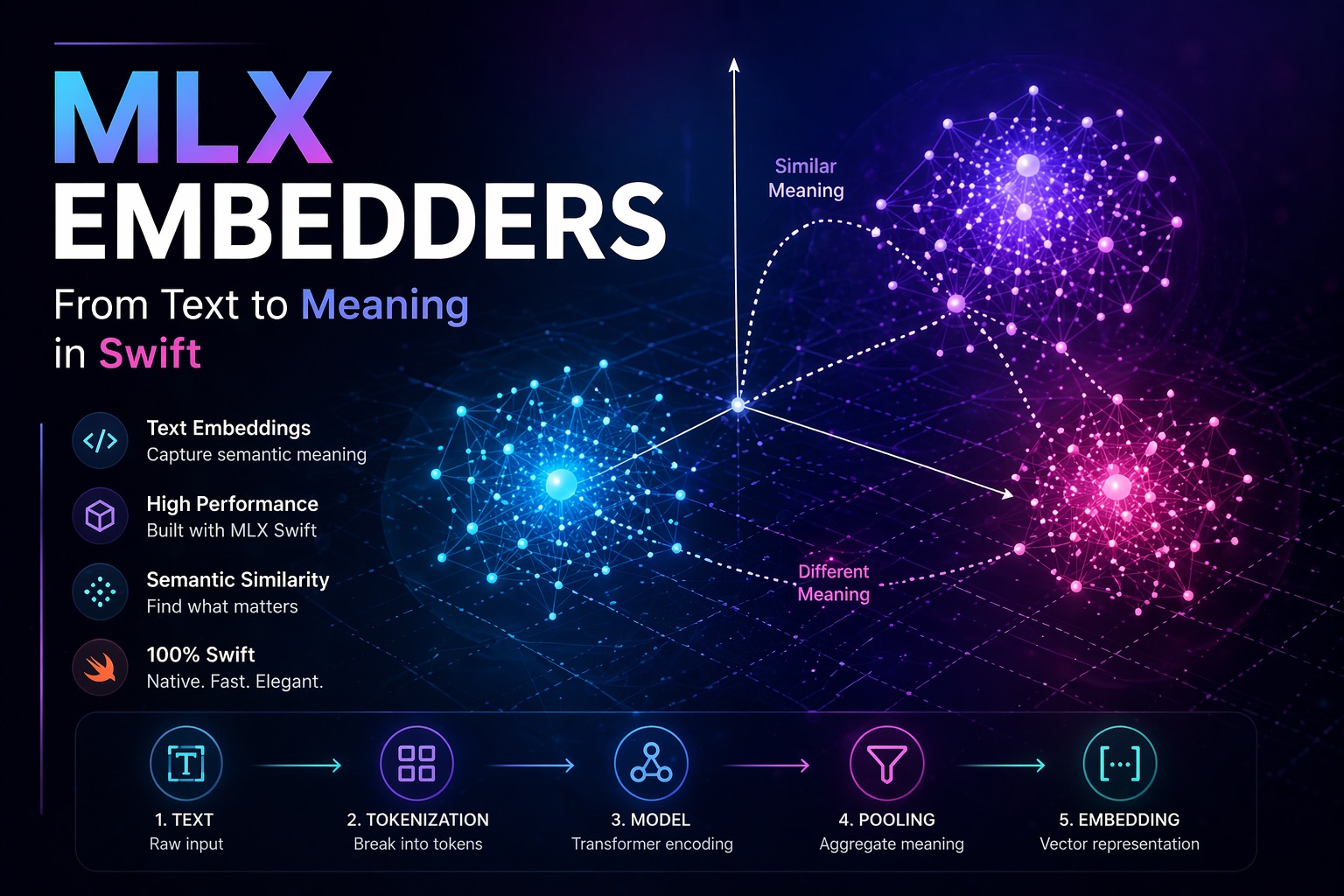
MLX Embedders in Swift: On-Device Text Embeddings for iOS
In Part 1 of this series, we built a minimal LLM inference pipeline on Apple Silicon using MLX Swift. In Part 2, we quantized a model from scratch and saw how 4-bit precision makes billion-parameter models tractable on a phone. This article introduces MLX Embedders, specifically the MLXEmbedders Swift library, and takes a different angle. Instead of generating text, we are going to encode meaning. A user types: “best hikes near a volcano.” A keyword search returns nothing useful. An embedding-based system returns exactly what they need, because it understands what the words mean, not just what they spell. That capability is what embeddings unlock, and it is the foundation of every serious AI feature in production today: semantic search, recommendation systems, RAG pipelines, and clustering. ...

